-
- The web archiving project has started at the beginning of 2017 in the HNMPCC National Széchényi Library,
the test period lasted until 2019. - The aim is to preserve and make searchable documents and information sources produced and distributed in digital form.
- The primary scope of collection is scientific, cultural, educational, and public sphere web content.
- Types of archiving:
– periodic harvests of selected Hungarian websites (by theme, genre, institution);
– events related harvests (news portal sections, relevant websites and blogs);
– snapshots of the Hungarian web space (servers under the .hu domain and other Hungary related content);
– individual backups of content shared publicly on social media (primarily pages/channels of institutions and organizations, in small quantities, for testing purposes). - The web archive uses open source, free software.
- Only a small part of the collection is public, for legal reasons. The entire archive is accessible from terminals located in the library’s reading room.
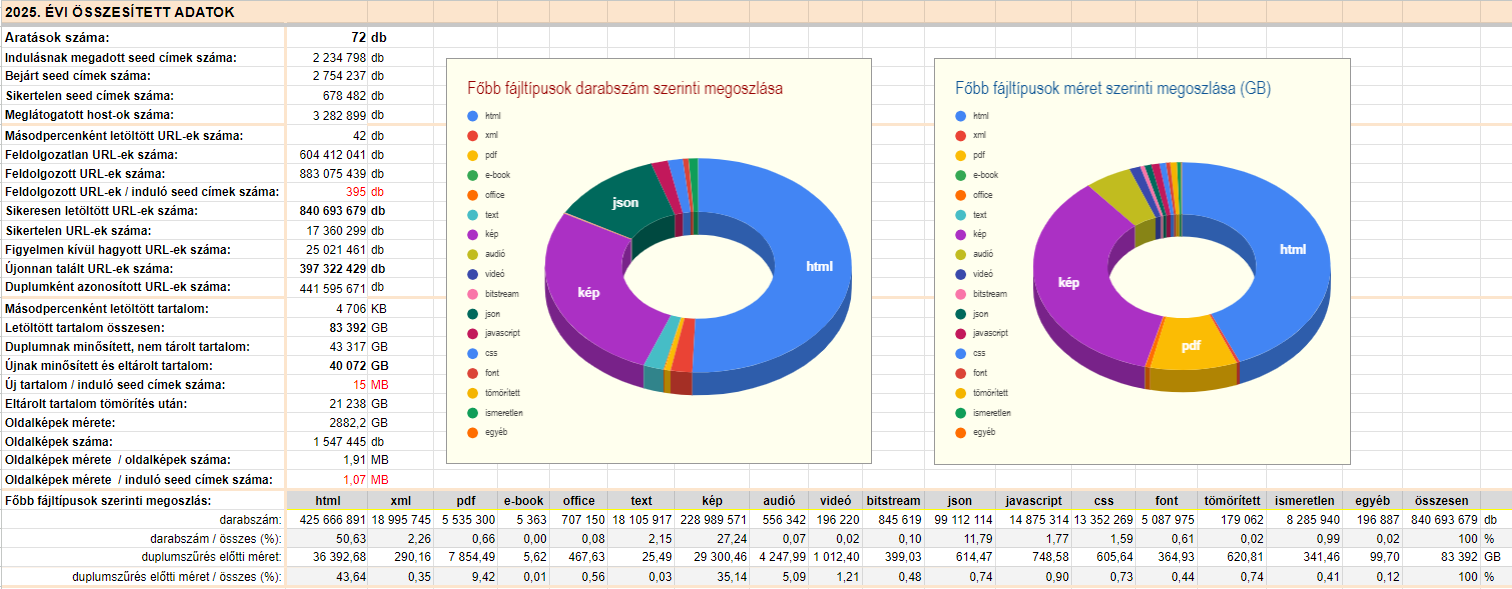
- Statistics at the end of 2025:
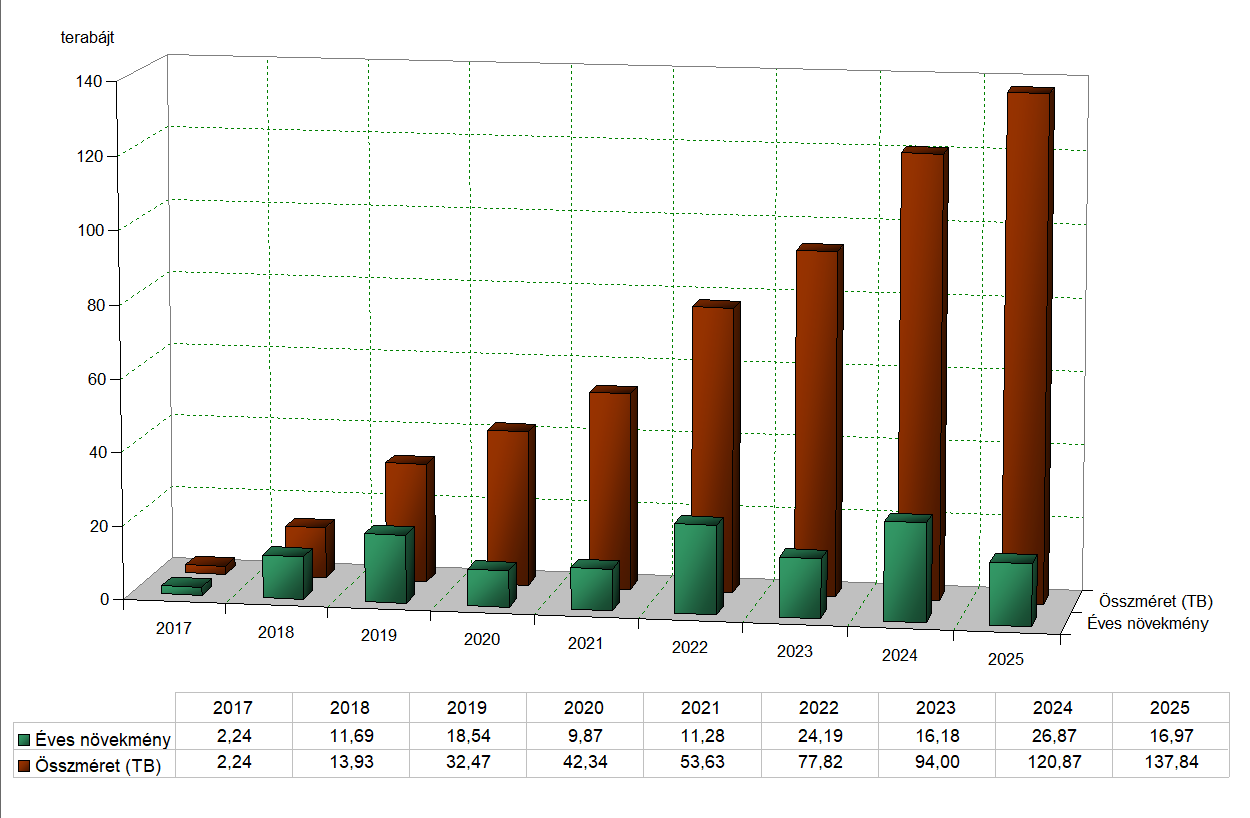
Growth and total size of the non-public archive
(after compression) - The web archiving project has started at the beginning of 2017 in the HNMPCC National Széchényi Library,
Closed archive:
21 thematic sub-collections (e.g. public collections, art, religion, education, government, tourism, lifestyle)
5 sub-collection by genre (e-periodicals, news portals, podcasts, Facebook, Instagram, X/Twitter)
26 event-based sub-collections (e.g. elections, sport events, war, pandemic, Katalin Karikó’s Nobel Prize)
1 geographical location-based sub-collection (Transcarpathia)
approx. 117 thousand selected websites saved quarterly with frontpage screenshots
approx. 942 thousand semi-automatically collected sites saved semiannually with frontpage screenshots
approx. 140 terabytes total size
Public archives:
585 selected and licensed or not subject to licensing sites saved quarterly
129 HNMPCC NSZL websites saved 1-2 times
25 websites maintained by the Balassi Institute, saved with two types of software
2 event-based sub-collection (Rákóczi Memorial Year, Foundation of the library by Ferenc Széchényi)
approx. 2.5 terabytes total size