 Hungarian National Museum Public Collection Centre National Széchényi Library is running webarchiving with a crawler that is similar to Google’s robot. The type of this crawler is usually Heritrix, that has developed by Internet Archive, and sometimes another tool called Brozzler or HTTrack. Robot is identifying itself as OSZKbot user-agent and if the targeted website has a robots.txt file, the robot is accepting all the restrictions that has set (the only exception if the provider authorizes HNMPCC NSZL to bypass these rules). System administrators can set up by the help of robots.txt that which part of their website can be harvested. However as it is important to preserve the layout and navigation functions, CSS, JavaScript, font type, layout and other necessary functional elements have to be allowed for the harvesting robot, even if these permissions are unnecessary for Google robot and other indexing robots.
Hungarian National Museum Public Collection Centre National Széchényi Library is running webarchiving with a crawler that is similar to Google’s robot. The type of this crawler is usually Heritrix, that has developed by Internet Archive, and sometimes another tool called Brozzler or HTTrack. Robot is identifying itself as OSZKbot user-agent and if the targeted website has a robots.txt file, the robot is accepting all the restrictions that has set (the only exception if the provider authorizes HNMPCC NSZL to bypass these rules). System administrators can set up by the help of robots.txt that which part of their website can be harvested. However as it is important to preserve the layout and navigation functions, CSS, JavaScript, font type, layout and other necessary functional elements have to be allowed for the harvesting robot, even if these permissions are unnecessary for Google robot and other indexing robots.
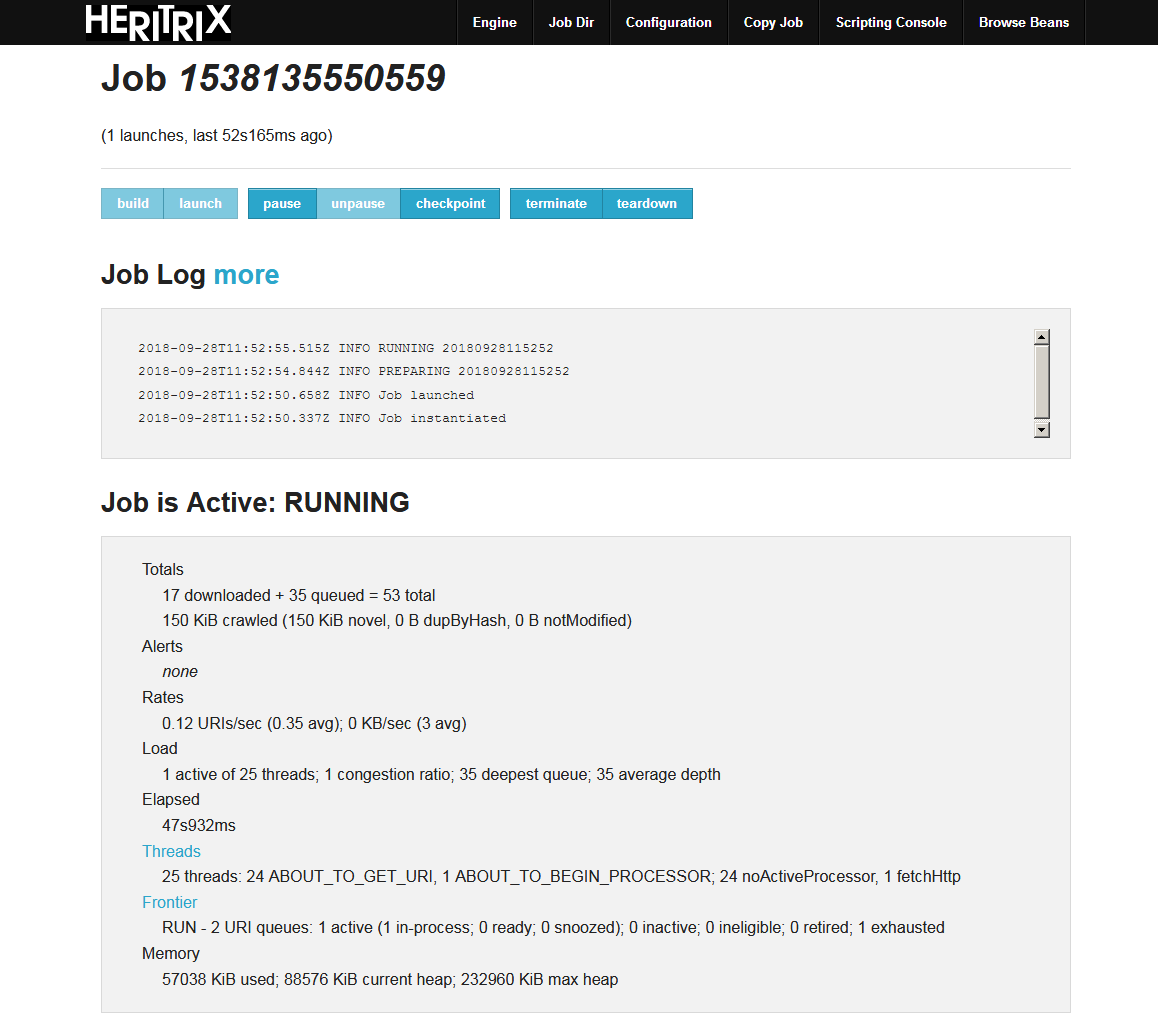
OSZKbot is only crawling public websites and usually not the whole websites with maximum deepness. Certainly, not crawling websites needs prior registration to use. It cannot download database contents if those are only available via a simple query form. Files with extremely big size, streaming media, downloadable video contents are also excluded. Robot is working on polite mode that means that it is not overloading a web server with rapidly frequent requests, it is not affecting the server’s latency for human users. Because of that, the harvesting process of a larger website sometimes could take several days. Harvesting is constantly repeating several times per year in order to crawl new or modified files.
Harvested web content has become a part of a non-public archive collection in WARC format. This archive is being planned to use for research purposes by respecting privacy and copyright, in the library intranet by dedicated workstations without the possibility to copy any of the content. Only the most important metadata (name, URL, topic) of those websites that can be found in this non-public collection will be publicly available together with a 300 pixel thumbnail about the starting page of each website (by non-readable quality).
In case of some websites the content (copyright) owners would be asked to sign a contract in order to include the harvested content of these websites in a public collection. This is a public demo collection primarily offering a showcase of capabilities and limits of web archiving technology. Among the archived version in each case a link points to the original URL of the archived website. Furthermore Google robot is being excluded from the web archive, in this way no one can found the archived version of a website by Google instead of the original one. To become a part of the public archive can be requested by the website owners by filling up a recommendation form.
Although Heritrix is the most up-to date archiving tool, it cannot handle many dynamic websites (with a large number of JavaScript and other code elements and a huge set of interactive functions). As a result, the archived website can be incomplete. Some elements can be missing, layout would not appearing on its full scale properly, internal links sometimes cannot function well, embedded programs, searching tools also would not work in a correct way. Therefore we are experimenting with other software besides the robot harvest, such as Webrecorder. A major aim of the public demo archive to demonstrate to the website owners, in which way their website can be preserves for longer term. We are happily support them by tests and recommendations to make their blog or website crawler- and archive-friendly, which is just as important as accessibility. We can also help to establish a personal or corporate web archive (for example to archive previous versions of his/her homepage or other online contents).