Az augusztus 25-én kezdődő Tokiói Nyári Paralimpiai Játékokról szóló hírrovatokkal, a Magyar Paralimpiai Bizottság honlapjával, továbbá a Bizottság és a magyar csapat közösségi média oldalaival egészítettük ki a NYAROL2020 nevű címlistát és elkezdtük ezek archiválását.
Webtér szintű seed kereső frissült
Elkészültek a kis méretű oldalképek a magyar webtér aratásához használt címlistához és a legtöbb cím esetében már az Internet Archive-ra mutató linkek is megjelennek a kereső találati listájában. Mivel ezzel az űrlappal az URL-ek mellett a weboldalak title adatában is lehet keresni, ezért az elmúlt hetekben egyenként megnéztük azt a 38.394 címet, ahol automatikusan nem sikerült a title-t begyűjteni. Az ellenőrzés eredményeként 18.738 működő webhelyet találtunk és 81 kivételével valamiféle nevet is sikerült hozzáadni ezekhez. A teljes címlista jelenleg 42.747 tételes.
Szakirodalmi bibliográfia frissítése
Főként 2020 óta megjelent publikációkkal bővült az internetes tartalmak megőrzésével foglalkozó szakirodalmi válogatásunk. A 2020. február 17-i korábbi állapothoz képest most 217 rekorddal – köztük szakdolgozatok és doktori disszertációk adataival – bővült a lista, mely így már 704 tételes és többféle formátumban is letölthető.
Webtér szintű seed kereső
A Webarchívum/Keresés menüpont alatt elérhető egy új kereső űrlap, amivel a webtér szintű aratásnál kiinduló (seed) címként használt URL-ek, valamint az ezekhez tartozó weboldalakról nagyrészt automatikus módszerekkel begyűjtött title metaadatok között lehet keresni. Az adatbázis most közel 441 ezer tételt tartalmaz és bár már többféle tisztítási fázison átment, még eléggé „szemetes”, sok benne a nem működő vagy duplum URL, a hiányzó vagy semmitmondó név. A ** NINCS CÍM ** jelzésű, hiányzó title adatok pótlása emberi munkával folyamatban van. Ugyancsak folyik a kis méretű oldalképek gyártása és az Internet Archive-ban levő mentésekre mutató linkek ellenőrzése, így ezek fokozatosan jelennek majd meg a találati listákban a következő hetekben.
TMT cikk a közösségi média megőrzéséről
A Tudományos és Műszaki Tájékoztatás idei 7. számában megjelent Drótos László cikke „Az idő fogságában – Ki őrzi meg a közösségi médiát?” címmel. A tanulmány a Facebook, az Instagram és a Twitter bejegyzések archiválhatóságára vonatkozó OSZK-s tesztek eredményét ismerteti, bemutatja a szóba jöhető módszereket és szoftvereket, valamint egy rövid nemzetközi kitekintést is ad erről a speciális szakterületről.
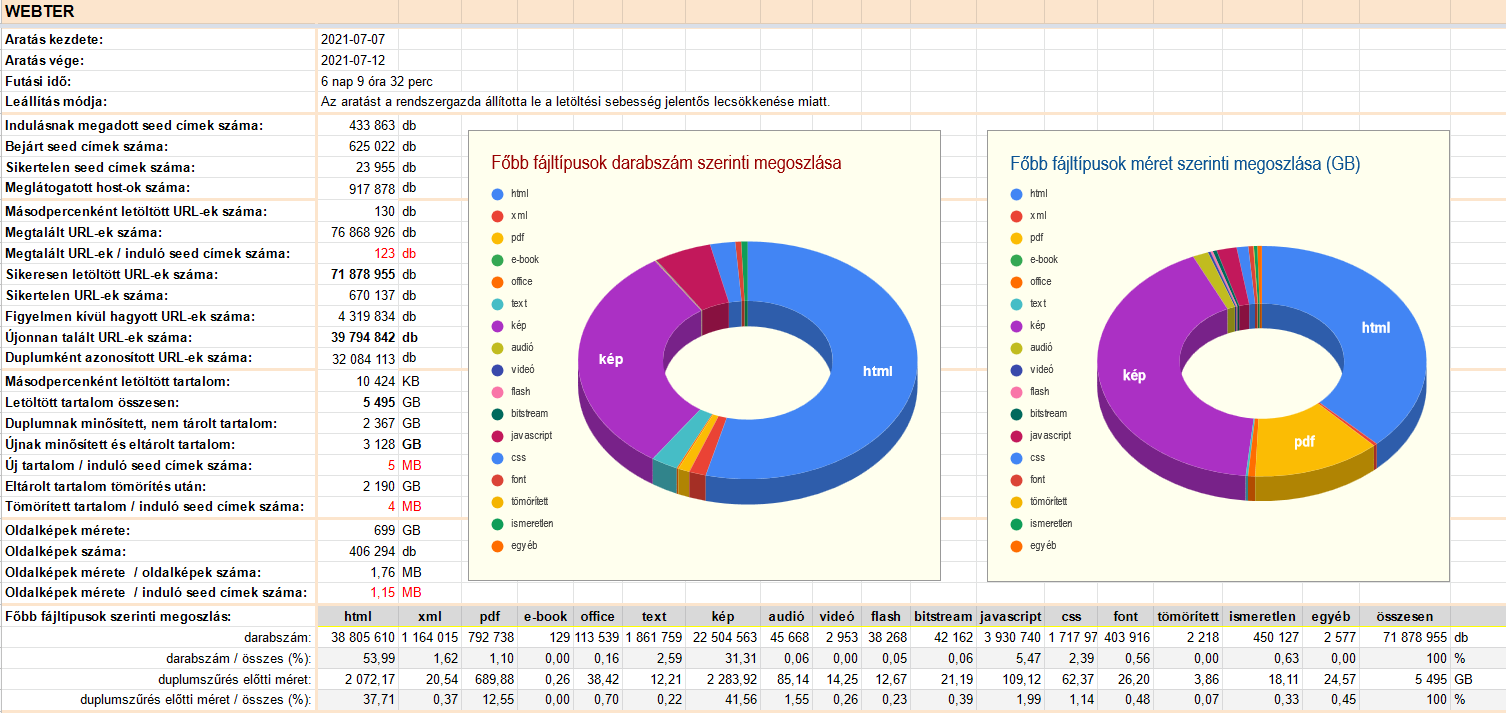
Nyári webtér aratás
Július 7. és 12. között lefutott egy újabb, félévente ismételt, „pillanatfelvétel” jellegű nagy aratás az összes eddig általunk ismert magyar domén és aldomén címről. A tavaly december végi 251 ezer tételes seed listához képest most jelentősen több, 434 ezer URL címről indítottuk el a robotot, amely 6 nap és 9 óra alatt közel 72 millió fájlt töltött le. Ennek több mint a fele volt az új tartalom, 3,2 terabájt összméretben. A részletesebb statisztika itt található. (Az oldalképekre vonatkozó adatok csak ideiglenesek, mert az ezeket készítő script kb. az egyharmadánál jár a feladatnak. Továbbá a belinkelt statisztikában nincs benne az a 12,5 ezer webszerver, amelyekhez nem tartozik robots.txt, mivel ezeket egy külön menetben arattuk le.)
{kind=link}
Középiskolásoknak a digitális megőrzéséről
Felkerült a honlapra egy középiskolásoknak szánt oktatási segédlet vázlata „Mentsük le az internetet! – Internetes tartalmak megőrzése intézményi és személyes archiválással” címmel. Ez a szöveg még 2019 végén készült a KDS pályázat keretében egy multimédiás tananyaghoz. A benne levő linkek és adatok most frissítve lettek.
MIA Wiki bővítés
Az elmúlt három hétben 50 új szócikkel, főként közösségi oldalak archiválásra is alkalmas eszközök leírásával bővítettük tovább az internetes tartalmak megőrzésével foglalkozó wikinket, amely így már 701 bejegyzésből áll és több mint 1430 linket tartalmaz külső forrásokra: https://webarchivum.oszk.hu/mediawiki/
IIPC GA és WAC
Zajlik az International Internet Preservation Consortium éves közgyűlése és konferenciája, melyet ezúttal is online rendeztek meg, összekapcsolva a 4. RESAW konferenciával. Mi most csak egy 5 perces összefoglalást tartottunk az OSZK Webarchívumának elmúlt egy évéről. Németh Márton prezentációja itt tölthető le.
Folytatódik a Facebook archiválás
Újra elkezdtük nyilvános Facebook fiókok idővonalát menteni, amivel tavaly kénytelenek voltunk leállni a cég által bevezetett technikai változtatások miatt. Most az ArchiveWeb.page nevű új Chrome kiegészítővel archiválunk, de az egyes posztokat külön nem mentjük, mert az nagyon időigényes. Első lépésben 14 történelmi témájú oldal idővonalát próbáltuk letölteni, ami az esetek felében az első bejegyzésig visszamenőleg sikerült is. A következő fázisban 64 hírportál és egyéb időszaki kiadvány Facebook oldaláról készítünk mentéseket, de ezeken olyan mennyiségű tartalom van, hogy néha még az utolsó egy hónap anyagának letöltése is nehézséget jelent.